Prepare OpenShift for Illumio Core
If the prerequisite steps are not performed prior to VEN and Kubelink installation, containerized environments and Kubelink may be disrupted.
Unique Machine ID
Some of the functionalities and services provided by the Illumio VEN and Kubelink depend on the Linux machine-id of each OpenShift cluster node. Each machine-id must be unique in order to take advantage of the functionalities. By default, the Linux OS generates a random machine-id to give each Linux host uniqueness. However, there are cases when machine-id's can be duplicated across machines. This is common across deployments that clone machines from a golden image, for example, spinning up virtual machines from VMware templates or creating Amazon EC2 instances from an AMI.
To verify machine-ids and resolve any duplicate machine-ids across nodes:
sshinto every node of the OpenShift cluster (master, infra, and worker) as the root user.Check the contents of the
/etc/machine-idfile. The output is a string of letters and numbers.If the machine-id string is unique for each node, then the environment is ok. If the machine-id is duplicated across any of the nodes, you must generate a machine-id for each node which has the same machine-id.
You can run the following command to view the output of machine-id:
cat /etc/machine-id
If the machine-id is duplicated, then run the command listed below to generate a new machine-id. You will also need to restart the atomic-OpenShift-node service on each node. If the machine-id is not duplicated, go to the next section.
rm -rf /etc/machine-id; touch /etc/machine-id; systemd-machine-id-setup; service atomic-OpenShift-node restart
Note
Check the machine-id again to verify that each machine has a unique machine-id.
Create Labels
For details on creating labels, see "Labels and Label Groups" in the Security Policy Guide.
The labels listed below are used in examples throughout this document. You are not required to use the same labels.
Name | Label type |
|---|---|
Openshift Infrastructure | Application |
Development | Environment |
HQ | Location |
Kubelink | Role |
Master | Role |
Infra | Role |
Compute | Role |
Create Pairing Profiles
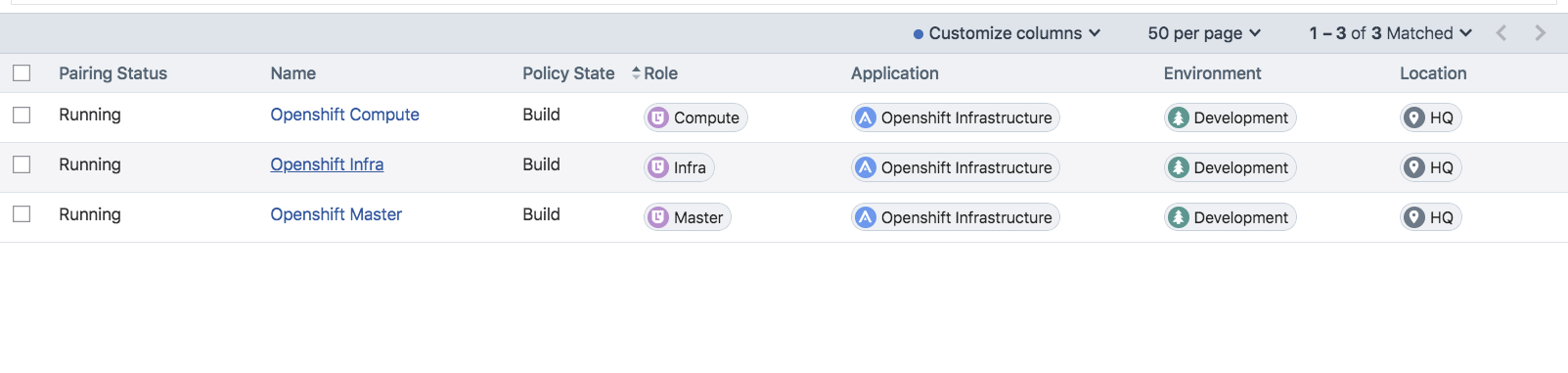
After creating labels for your OpenShift cluster nodes, you can use those labels to create pairing profiles. You do not need to create pairing profiles for container workloads.
For ease of configuration and management, consider applying the same Application, Environment, and Location labels across all nodes of the same OpenShift cluster. The screenshot below show examples of three pairing profiles for one OpenShift Enterprise cluster. The pairing profiles are used for pairing either master, compute, or infrastructure nodes of an OpenShift cluster.
Tip
It is recommended that all pairing profiles for OpenShift nodes not use Enforced policy state.
Move into Enforced state after you have completed all other configuration steps in this guide (setup Kubelink, discover services, and write rules).