PCE Failures and Recoveries
This section describes how the PCE handles various types of possible failures. It tells whether the failure can be handled automatically by the PCE and, if not, what manual intervention you need to perform to remedy the situation.
PCE Core Deployments and High Availability (HA)
The most common PCE Core deployments are either 2x2 or 4x2 setup.
For High Availability (HA) purpose, the PCE nodes can be deployed as 2 separate pairs (either 1core+1data or 2core+1data respectively) in separate data centers.
For high availability, the database services run in a primary replica mode with the primary service running on either of the data nodes.
Note
Both data nodes (data0 & data1) are always working as "active". Therefore, one of the data nodes (data1) is not on a "warm" standby that would become "active" when the primary data node has failed.
Types of PCE Failures
These are the general kinds of failures that can occur with a PCE deployment:
PCE-VEN network partition: A network partition occurs that cuts off communication between the PCE and VENs.
PCE service failure: One or more of the PCE's services fail on a node.
PCE node failure: One of the PCE's core or data nodes fails.
PCE split cluster failure (site failure): One data plus half the total number of core nodes fail.
PCE cluster network partition: A network partition occurs between two halves of a PCE cluster but all nodes are still functioning.
Multi-node traffic database failure: If the traffic database uses the optional multi-node configuration, the coordinator and worker nodes can fail.
Complete PCE failure: The entire PCE cluster fails or is destroyed and must be rebuilt.
Failure-to-Recovery Stages
For each failure case, this document provides the following information (when applicable):
Stage | Details |
|---|---|
Preconditions | Any required or recommended pre-conditions that you are responsible for to recover from the failure. For example, in some failure cases, Illumio assumes you regularly exported a copy of the primary database to an external system in case you needed to recover the database. |
Failure behavior | The behavior of the PCE and VENs from the time the failure occurs to recovery. It can be caused by the failure itself or by the execution of recovery procedures. |
Recovery | A description of how the system recovers from the failure incident to resume operations, which might be automatic or require manual intervention on the PCE or VEN. When intervention is required, the steps are provided. Includes the following items:
|
Full Recovery (not always applicable) | In some cases, additional steps might be required to revert the PCE to its normal, pre-failure operating state. This situation is usually a planned activity that can be scheduled. |
Legend for PCE Failure Diagrams
The following diagram symbols illustrate the affected parts of the PCE in a failure:
Dotted red line: Loss of network connectivity, but all nodes are still functioning
Dotted red X: Failure or loss of one or more nodes, such as when a node is shut down or stops functioning
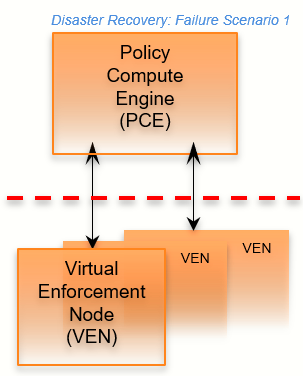
PCE-VEN Network Partition
In this failure case, a network partition occurs between the PCE and VENs, cutting off communication between the PCE and all or some of its VENs. However, the PCE and VENs are still functioning.
Stage | Details |
|---|---|
Preconditions | None |
Failure Behavior | PCE
VENs
|
Recovery |
|
Service Failure
In this failure case, one of the PCE's services fails on a node.
Stage | Details |
|---|---|
Preconditions | None. |
Failure Behavior | PCE
VENs
|
Recovery |
|
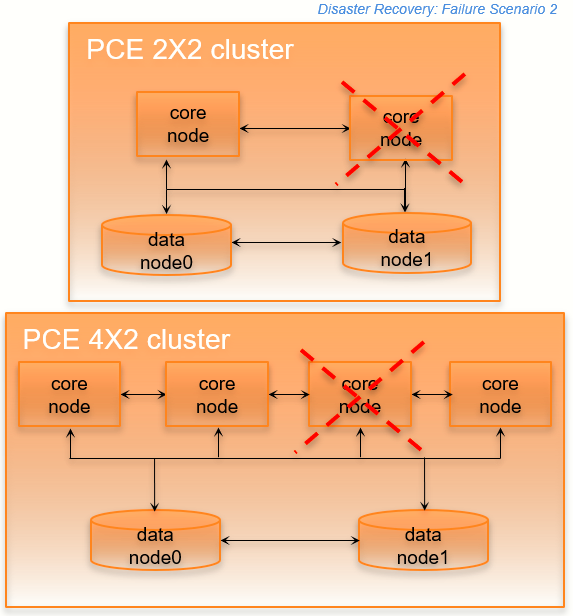
Core Node Failure
In this failure case, one of the core nodes completely fails. This situation occurs anytime a node is not communicating with any of the other nodes in the cluster; for example, a node is destroyed, the node's SDS fails, or the node is powered off or disconnected from the cluster.
Stage | Details |
|---|---|
Preconditions | The load balancer must be able to run application level health checks on each of the core nodes in the PCE cluster, so that it can be aware at all times whether a node is available. ImportantWhen you use a DNS load balancer and need to provision a new core node to recover from this failure, the |
Failure Behavior | PCE
VENs
|
Recovery |
|
Full Recovery | Either recover the failed node or provision a new node and join it to the cluster. |
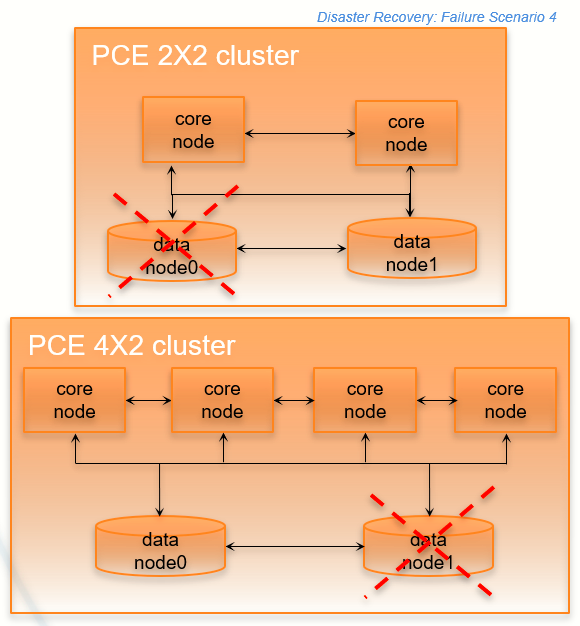
Data Node Failure
In this failure scenario, one of the data nodes fails completely.
Stage | Details |
|---|---|
Preconditions | You should continually monitor the replication lag of the replica database to make sure it is in sync with the primary database. You can accomplish this precondition by monitoring the sudo -u ilo-pce illumio-pce-db-management show-replication-info |
Failure Behavior | PCE
VENs
|
Recovery |
|
Full Recovery | When the failed data node is recovered or a new node is provisioned, it registers with PCE and is added as an active member of the cluster. This node is designated as the replica database and will replicate all the data from the primary database. |
Primary Database Doesn't Start
In this failure case, the database node fails to start.
Stage | Details |
|---|---|
Preconditions | The primary database node does not start. |
Failure Behavior | The database cannot be started. Therefore, the entire PCE cluster cannot be started. |
Full Recovery | Recovery type: Manual. You have two recovery options:
WarningPromoting a replica to primary risks data loss Illumio strongly recommends that this option be a last resort because of the potential for data loss. When the PCE Supercluster is affected by this problem, you must also restore data on the promoted primary database. |
Primary Database Doesn't Start When PCE Starts
In this failure case, the database node fails to start when the PCE starts or restarts.
The following recovery information applies only when the PCE starts or restarts. When the PCE is already running and the primary database node fails, database failover will occur normally and automatically, and the replica database node will become the primary node.
Stage | Details |
|---|---|
Preconditions | The primary database node does not start during PCE startup. This issue could occur because of an error on the primary node. Even when no error occurred, you might start the replica node first and then be interrupted, causing a delay in starting the primary node that exceeds the timeout. |
Failure Behavior | The database cannot be started. Therefore, the entire PCE cluster cannot be started. |
Full Recovery | Recovery type: Manual. You have two recovery options:
WarningPromoting a replica to primary risks data loss Consider this option as a last resort because of the potential for data loss, depending on the replication lag. When you decide on the second option, on the replica database node, run the following command: sudo ilo-pce illumio-pce-ctl promote-data-node <core-node-ip-address> This command promotes the node to be the primary database for the cluster whose leader is at the specified IP address. |
Site Failure (Split Clusters)
In this failure type, one of the data nodes plus half the total number of core nodes fail, while the surviving data and remaining core nodes are still functioning.
In a 2x2 deployment, a split cluster failure means the loss of one of these node combinations:
Data0 and one core node
Data1 and one core node
In a 4x2 deployment, a split cluster failure means the loss of one of these node combinations::
Data0 and two core nodes
Data1 and two core nodes
This type of failure can occur when the PCE cluster is split across two separate physical sites or availability zones with network latency greater than 10ms, and a site failure causes half the nodes in the cluster to fail. A site failure is one case that can cause this type of failure; however, split cluster failures can also occur in a single site deployment when multiple nodes fails simultaneously for any reason.
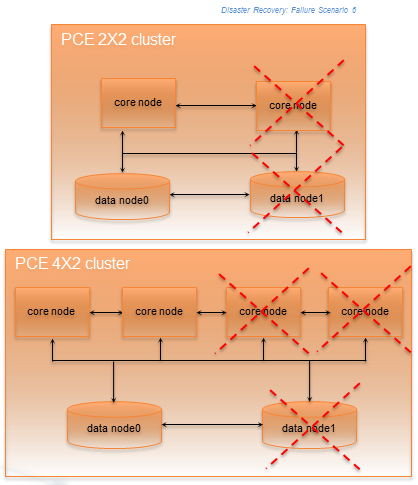
Split Cluster Failure Involving Data1
In this failure case, data1 and half the core nodes completely fail.
Stage | Details |
|---|---|
Preconditions | None. |
Failure Behavior | PCE
VENs
|
Recovery |
|
Full Recovery | Either recover the failed nodes or provision new nodes and join them to the cluster. For recovery information, see Replace a Failed Node. |
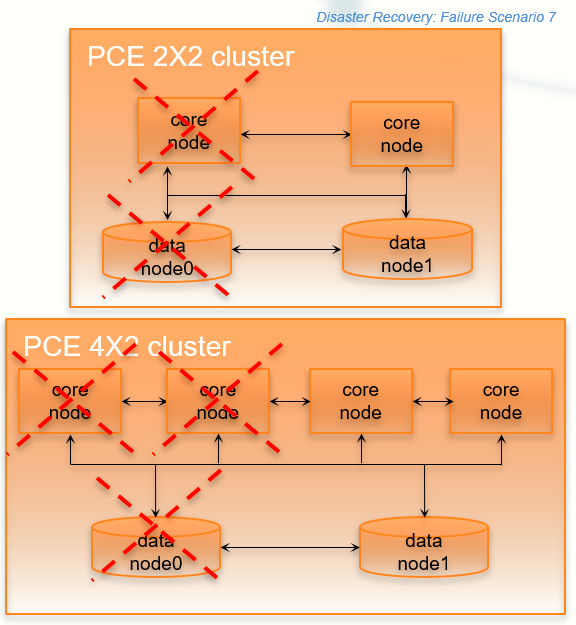
Split Cluster Failure Involving Data0
In this failure case, data0 and half of the total number of core nodes completely fail.
Stage | Details |
|---|---|
Preconditions | CautionWhen reverting the standalone cluster back to a full cluster, you must be able to control the recovery process so that each recovered node is powered on and re-joined to the cluster one node at a time (while the other recovered nodes are powered off). Otherwise, the cluster could become corrupted and need to be fully rebuilt. |
Failure Behavior | PCE
VENs
|
Recovery |
|
Full Recovery | See Revert Standalone Cluster Back to a Full Cluster for information. |
Configure Data1 and Core Nodes as Standalone Cluster
To enable the surviving data1 and core nodes to operate as a standalone 2x2 or 4x2 cluster, follow these steps in this exact order.
On the surviving data1 node and all surviving core nodes, stop the PCE software:
sudo -u ilo-pce illumio-pce-ctl stop
On any surviving core node, promote the core node to be a standalone cluster leader:
sudo -u ilo-pce illumio-pce-ctl promote-cluster-leader
On the surviving data1 node, promote the data1 node to be the primary database for the new standalone cluster:
sudo -u ilo-pce illumio-pce-ctl promote-data-node <promoted-core-node-ip-address>
For the IP address, enter the IP address of the promoted core node from step 2.
(4x2 clusters only) On the other surviving core node, join the surviving core node to the new standalone cluster:
sudo -u ilo-pce illumio-pce-ctl cluster-join <promoted-core-node-ip-address> --split-cluster
For the IP address, enter the IP address of the promoted core node from step 2.
Back up the surviving data1 node.
Revert Standalone Cluster Back to a Full Cluster
To revert back to a 2x2 or 4x2 cluster, follow these steps in this exact order:
Important
When you plan to recover the failed nodes and the PCE software is configured to auto-start when powered on (the default behavior for a PCE RPM installation), you must power on every node and re-join them to the cluster one node at a time, while the other nodes are powered off and the PCE is not running on the other nodes. Otherwise, your cluster might become corrupted and need to be fully rebuilt.
Recover one of the failed core nodes or provision a new core node.
If you provisioned a new core node, run the following command on any existing node in the cluster (not the new node you are about to add). For
ip_address, substitute the IP address of the new node.sudo -u ilo-pce illumio-pce-ctl cluster-nodes allow ip_addressOn the recovered or new core node, start the PCE software and enable the node to join the cluster:
sudo -u ilo-pce illumio-pce-ctl cluster-join <promoted-core-node-ip-address>
For the IP address, enter the IP address of the promoted core node.
(4x2 clusters only) For the other recovered or new core nodes, repeat steps 1-3.
Recover the failed data0 nodes or provision a new data0 node.
If you provisioned a new data node, run the following command on any existing node in the cluster (not the new node you are about to add). For
ip_address, substitute the IP address of the new node.sudo -u ilo-pce illumio-pce-ctl cluster-nodes allow ip_addressOn the recovered data0 or new data0 node, start the PCE software and enable the node to join the cluster:
sudo -u ilo-pce illumio-pce-ctl cluster-join <promoted-core-node-ip-address>
For the IP address, enter the IP address of the promoted core node.
On the surviving data1 node and all core nodes, remove the standalone configuration for the nodes that you previously promoted during failure:
sudo -u ilo-pce illumio-pce-ctl revert-node-config
Note
Run this command so that the nodes that you previously promoted during the failure no longer operate as a standalone cluster.
Verify that the cluster is in the RUNNING state:
sudo -u ilo-pce illumio-pce-ctl cluster-status --wait
Verify that you can log into the PCE web console.
Note
In rare cases, you might receive an error when attempting to log into the PCE web console. When this happens, restart all nodes and try logging in again:
sudo -u ilo-pce illumio-pce-ctl restart
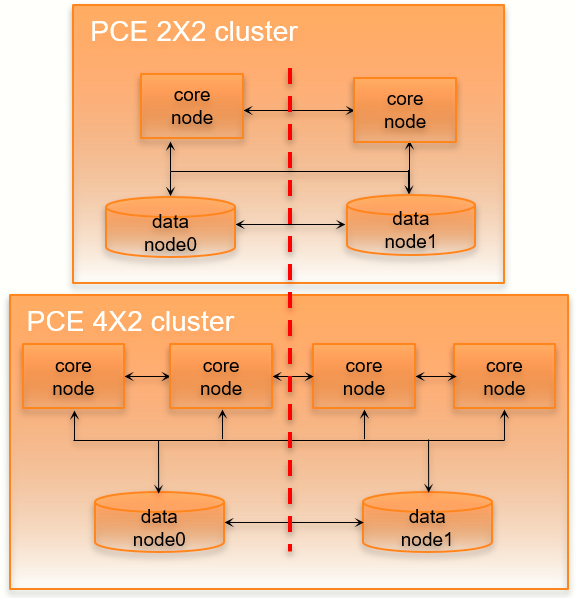
Cluster Network Partition
In this failure case, the network connection between half your PCE cluster is severed, cutting off all communication between the each half of the cluster. However, all nodes in the cluster are still functioning.
Illumio defines “half a cluster” as one data node plus half the total number of core nodes in the cluster.
Stage | Details |
|---|---|
Preconditions | None. |
Failure behavior | PCE
VENs
|
Recovery |
|
Full Recovery | No additional steps are required to revert the PCE to its normal, pre-failure operating state. When network connectivity is restored, the data1 half of the cluster automatically reconnects to the data0 half of the cluster. The PCE then restarts all services on the data1 half of the cluster. |
Multi-Node Traffic Database Failure
If the traffic database uses the optional multi-node configuration, the coordinator and worker nodes can fail.
For information about multi-node traffic database configuration, see "Scale Traffic Database to Multiple Nodes" in the PCE Installation and Upgrade Guide.
Coordinator primary node failure
If the coordinator master completely fails, all the data-related PCE applications might be unavailable for a brief period. All other PCE services should be operational.
Recovery is automatic after the failover timeout. The coordinator replica will be promoted to the primary, and all data-related applications should work as usual when the recovery is done.
Warning
Any unprocessed traffic flow data on the coordinator primary will be lost until the coordinator primary is back to normal.
Coordinator primary does not start
If the coordinator primary does not start, the PCE will not function as usual.
There are two options for recovery:
Find the root cause of the failure and fix it. Contact Illumio Support if needed.
Promote a replica coordinator node to primary.
Warning
Promoting a replica coordinator to a primary can result in data loss. Use this recovery procedure only as a last resort.
To promote a replica coordinator node to primary:
sudo -u ilo-pce illumio-pce-ctl promote-coordinator-node cluster-leader-addressWorker primary node nailure
If the worker's primary node fails, all data-related applications might be unavailable briefly. All other PCE services should be operational.
Recovery is automatic after the failover timeout. The worker replica will be promoted to the primary. All data-related applications should work as usual once the recovery is done.
Warning
Any data not replicated to the replica worker node before the failure will be lost.
Worker primary does not start
If the worker primary does not start, the PCE will not function as usual.
There are two options for recovery:
Find the root cause of the failure and fix it. Contact Illumio Support if needed.
Promote the corresponding replica worker node to the primary.
Warning
Promoting a replica worker to primary can result in data loss. Use this recovery procedure only as a last resort.
To promote a replica worker node to primary, find out the corresponding replica worker for the failed primary node. Run the following command to list the metadata information for all the workers. Get the IP address of the replica for the failed primary:
sudo -u ilo-pce illumio-pce-db-management traffic citus-worker-metadata
Promote the replica worker node to primary:
sudo -u ilo-pce illumio-pce-ctl promote-worker-node core-node-ipComplete Cluster Failure
In this rare failure case, the entire PCE cluster has failed.
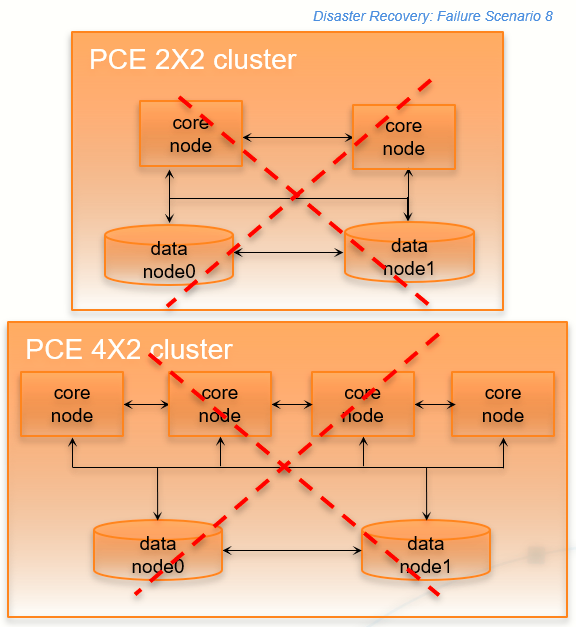
Stage | Details |
|---|---|
Preconditions | Illumio assumes that you have met the following conditions before the failure occurs for this failure case. IMPORTANT: You must consistently and frequently back up the PCE primary database to an external storage system that can be used for restoring the primary database after this type of failure. You need access to this backup database file to recover from this failure case. The
|
Failure behavior | PCE
VENs
|
Recovery |
|
Full Recovery | See Complete Cluster Recovery for full recovery information; perform all the listed steps on the restored primary cluster. |
Complete Cluster Recovery
Recovering from this failure case requires performing the following tasks:
Power on all nodes in the secondary PCE cluster.
Use the database backup file from your most recent backup and restore the backup on the primary database node.
To restore the PCE database from backup, perform the following steps:
On all nodes in the PCE cluster, stop the PCE software:
sudo -u ilo-pce illumio-pce-ctl stop
On all nodes in the PCE cluster, start the PCE software at runlevel 1:
sudo -u ilo-pce illumio-pce-ctl start --runlevel 1
Determine the primary database node:
sudo -u ilo-pce illumio-pce-db-management show-master
On the primary database node, restore the database:
sudo -u ilo-pce illumio-pce-db-management restore --file <location of prior db dump file>
Migrate the database by running this command:
sudo -u ilo-pce illumio-pce-db-management migrate
Copy the Illumination data file from the primary database to the other data node. The file is located in the following directory on both nodes:
<persistent_data_root>/redis/redis_traffic_0_master.rdb
Bring the PCE cluster to runlevel 5:
sudo -u ilo-pce illumio-pce-ctl set-runlevel 5
Verify that you can log into the PCE web console.
PCE-Based VEN Distribution Recovery
When you rely on the PCE-based distribution of VEN software, after you have recovered from a PCE cluster failure, you need to reload or redeploy the PCE VEN Library.
When you have at least one PCE core node unaffected by the failure, you can redeploy the VEN library to the other nodes.
When the failure is catastrophic and you have to replace the entire PCE cluster, you need to reload the PCE's VEN library. See VEN Administration Guide for information.
Restore VENs Paired to Failed PCE
A failed PCE does not receive information from VENs paired with it. This lack of connectivity can result in stale IP addresses and other information recorded for the VENs. Additionally, other PCEs might also have this stale information only. When the PCE regains connectivity, the PCE eventually marks those uncommunicative VENs “offline” and removes them from the policy.
To resolve this situation, you must delete the “offline” workloads from the PCE by using the PCE web console or the REST API. After deleting the VENs, you can re-install and re-activate the affected VENs on the affected workloads.