Site Failure (Split Clusters)
In this failure type, one of the data nodes plus half the total number of core nodes fail, while the surviving data and remaining core nodes are still functioning.
In a 2x2 deployment, a split cluster failure means the loss of one of these node combinations:
Data0 and one core node
Data1 and one core node
In a 4x2 deployment, a split cluster failure means the loss of one of these node combinations::
Data0 and two core nodes
Data1 and two core nodes
This type of failure can occur when the PCE cluster is split across two separate physical sites or availability zones with network latency greater than 10ms, and a site failure causes half the nodes in the cluster to fail. A site failure is one case that can cause this type of failure; however, split cluster failures can also occur in a single site deployment when multiple nodes fails simultaneously for any reason.
Split Cluster Failure Involving Data1
In this failure case, data1 and half the core nodes completely fail.
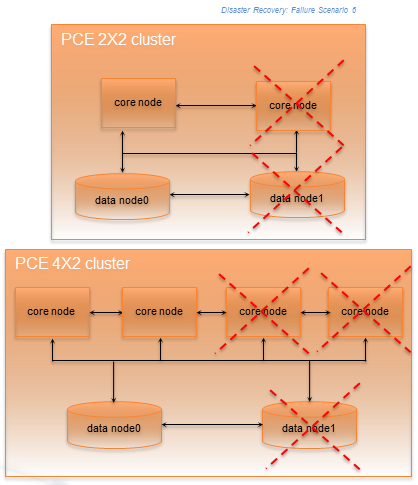
Stage | Details |
|---|---|
Preconditions | None. |
Failure Behavior | PCE
VENs
|
Recovery |
|
Full Recovery | Either recover the failed nodes or provision new nodes and join them to the cluster. For recovery information, see Replace a Failed Node. |
Split Cluster Failure Involving Data0
In this failure case, data0 and half of the total number of core nodes completely fail.
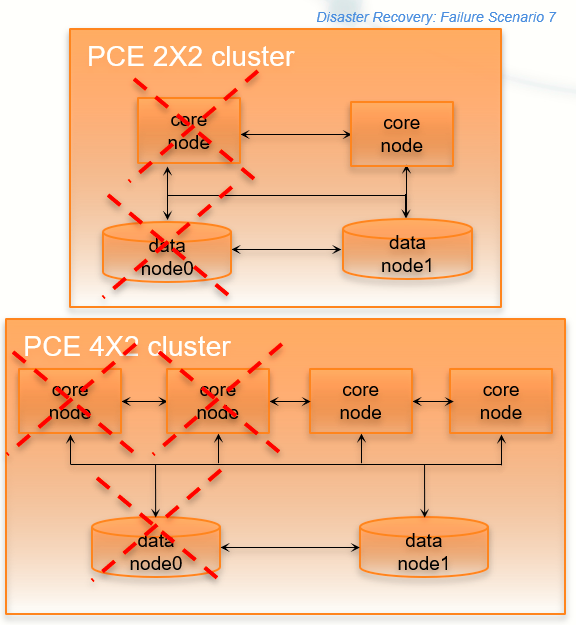
Stage | Details |
|---|---|
Preconditions | CautionWhen reverting the standalone cluster back to a full cluster, you must be able to control the recovery process so that each recovered node is powered on and re-joined to the cluster one node at a time (while the other recovered nodes are powered off). Otherwise, the cluster could become corrupted and need to be fully rebuilt. |
Failure Behavior | PCE
VENs
|
Recovery |
|
Full Recovery | See Revert Standalone Cluster Back to a Full Cluster for information. |
Configure Data1 and Core Nodes as Standalone Cluster
To enable the surviving data1 and core nodes to operate as a standalone 2x2 or 4x2 cluster, follow these steps in this exact order.
On the surviving data1 node and all surviving core nodes, stop the PCE software:
sudo -u ilo-pce illumio-pce-ctl stop
On any surviving core node, promote the core node to be a standalone cluster leader:
sudo -u ilo-pce illumio-pce-ctl promote-cluster-leader
On the surviving data1 node, promote the data1 node to be the primary database for the new standalone cluster:
sudo -u ilo-pce illumio-pce-ctl promote-data-node <promoted-core-node-ip-address>
For the IP address, enter the IP address of the promoted core node from step 2.
(4x2 clusters only) On the other surviving core node, join the surviving core node to the new standalone cluster:
sudo -u ilo-pce illumio-pce-ctl cluster-join <promoted-core-node-ip-address> --split-cluster
For the IP address, enter the IP address of the promoted core node from step 2.
Back up the surviving data1 node.
Revert Standalone Cluster Back to a Full Cluster
To revert back to a 2x2 or 4x2 cluster, follow these steps in this exact order:
Important
When you plan to recover the failed nodes and the PCE software is configured to auto-start when powered on (the default behavior for a PCE RPM installation), you must power on every node and re-join them to the cluster one node at a time, while the other nodes are powered off and the PCE is not running on the other nodes. Otherwise, your cluster might become corrupted and need to be fully rebuilt.
Recover one of the failed core nodes or provision a new core node.
If you provisioned a new core node, run the following command on any existing node in the cluster (not the new node you are about to add). For
ip_address, substitute the IP address of the new node.sudo -u ilo-pce illumio-pce-ctl cluster-nodes allow ip_addressOn the recovered or new core node, start the PCE software and enable the node to join the cluster:
sudo -u ilo-pce illumio-pce-ctl cluster-join <promoted-core-node-ip-address>
For the IP address, enter the IP address of the promoted core node.
(4x2 clusters only) For the other recovered or new core nodes, repeat steps 1-3.
Recover the failed data0 nodes or provision a new data0 node.
If you provisioned a new data node, run the following command on any existing node in the cluster (not the new node you are about to add). For
ip_address, substitute the IP address of the new node.sudo -u ilo-pce illumio-pce-ctl cluster-nodes allow ip_addressOn the recovered data0 or new data0 node, start the PCE software and enable the node to join the cluster:
sudo -u ilo-pce illumio-pce-ctl cluster-join <promoted-core-node-ip-address>
For the IP address, enter the IP address of the promoted core node.
On the surviving data1 node and all core nodes, remove the standalone configuration for the nodes that you previously promoted during failure:
sudo -u ilo-pce illumio-pce-ctl revert-node-config
Note
Run this command so that the nodes that you previously promoted during the failure no longer operate as a standalone cluster.
Verify that the cluster is in the RUNNING state:
sudo -u ilo-pce illumio-pce-ctl cluster-status --wait
Verify that you can log into the PCE web console.
Note
In rare cases, you might receive an error when attempting to log into the PCE web console. When this happens, restart all nodes and try logging in again:
sudo -u ilo-pce illumio-pce-ctl restart